
Land use and land cover samples and their metadata organized in a database with web services for discovery and access.
Nowadays, big volumes of images are generated by Earth observation satellites, with different spatial, temporal and spectral resolutions, and freely disseminated to society. From these large volumes of satellite images, analysis of time series derived from these images and machine learning methods have been widely used to identify and classify land use and land cover (LULC) information, including agricultural crops. These methods are generally supervised and therefore need a large set of LULC samples for training, which must represent the classes to be identified by the classifier. In the classification of LULC, good quality samples have a direct impact on the accuracy of the generated maps. Therefore, it is important to invest in new methods and techniques to help specialists collect, store and select good quality LULC samples.
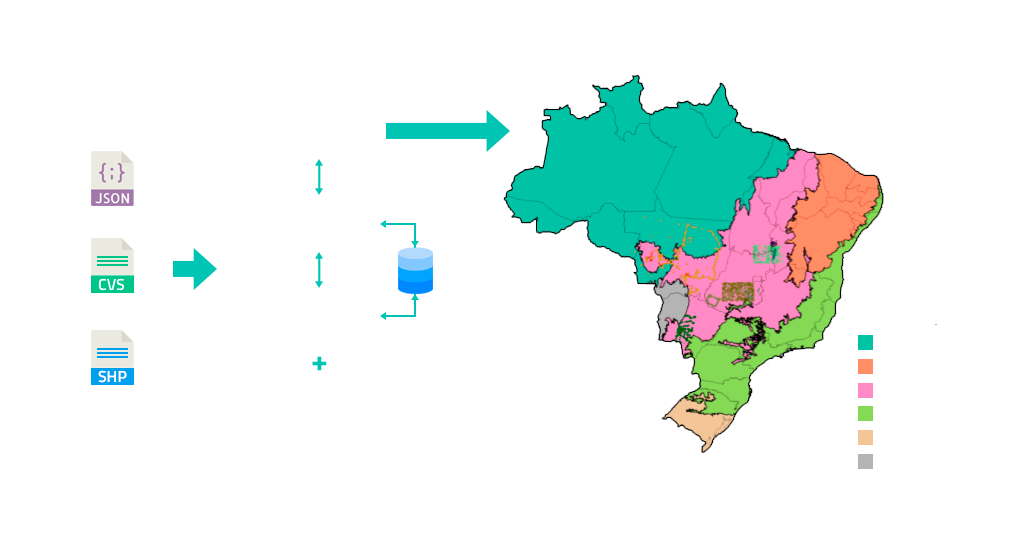
In the BDC project, we used LULC samples collected by different projects and individuals using different methods such as in situ fieldwork and visual interpretation of high resolution satellite images. Thus, we keep these samples with adequate metadata that characterize their differences and organize them in a shared database to facilitate the reproducibility of the experiments. In addition, we have developed tools to easily discover, query, access and process this shared sample database.
The SAMPLE-DB (Sample Database) provides a data model that represents land use and land cover samples collected by different projects and individuals. SAMPLE-DB-UTILS, has utility functions that perform the transformation of different data formats to be stored by SAMPLE-DB and SAMPLE-WS (Sample Web Service) provides a high-level interface to access stored data.
For more information about the toolset, see: